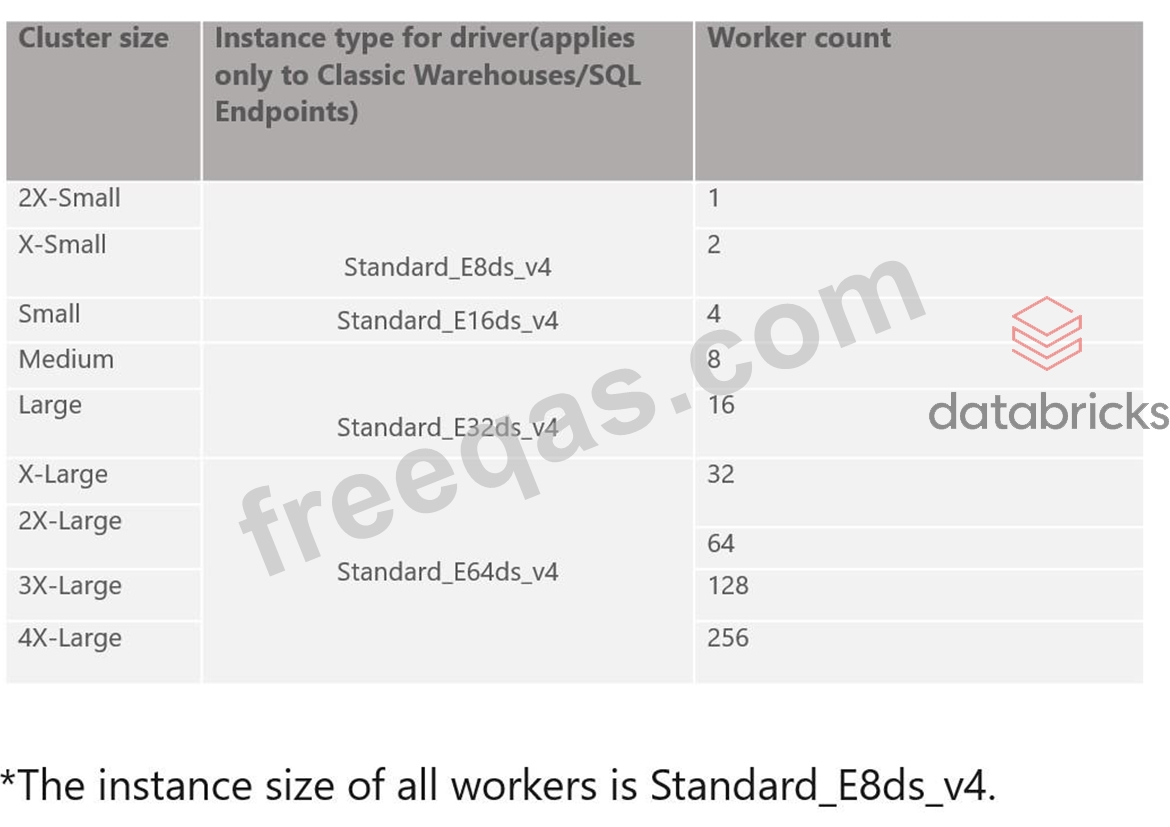
The data analyst team had put together queries that identify items that are out of stock based on orders and replenishment but when they run all together for final output the team noticed it takes a really long time, you were asked to look at the reason why queries are running slow and identify steps to improve the performance and when you looked at it you noticed all the code queries are running sequentially and using a SQL endpoint cluster. Which of the following steps can be taken to resolve the issue?
Here is the example query
1.--- Get order summary
2.create or replace table orders_summary
3.as
4.select product_id, sum(order_count) order_count
5.from
6. (
7. select product_id,order_count from orders_instore
8. union all
9. select product_id,order_count from orders_online
10. )
11.group by product_id
12.-- get supply summary
13.create or repalce tabe supply_summary
14.as
15.select product_id, sum(supply_count) supply_count
16.from supply
17.group by product_id
18.
19.-- get on hand based on orders summary and supply summary
20.
21.with stock_cte
22.as (
23.select nvl(s.product_id,o.product_id) as product_id,
24. nvl(supply_count,0) - nvl(order_count,0) as on_hand
25.from supply_summary s
26.full outer join orders_summary o
27. on s.product_id = o.product_id
28.)
29.select *
30.from
31.stock_cte
32.where on_hand = 0

Which of the following statements can be used to test the functionality of code to test number of rows in the table equal to 10 in python?
row_count = spark.sql("select count(*) from table").collect()[0][0]
Each configuration below is identical to the extent that each cluster has 400 GB total of RAM, 160 total cores and only one Executor per VM.
Given a job with at least one wide transformation, which of the following cluster configurations will result in maximum performance?
Incorporating unit tests into a PySpark application requires upfront attention to the design of your jobs, or a potentially significant refactoring of existing code.
Which statement describes a main benefit that offset this additional effort?
A data engineer wants to reflector the following DLT code, which includes multiple definition with very similar code:
In an attempt to programmatically create these tables using a parameterized table definition, the data engineer writes the following code.
The pipeline runs an update with this refactored code, but generates a different DAG showing incorrect configuration values for tables.
How can the data engineer fix this?
Enter your email address to download Databricks.Databricks-Certified-Professional-Data-Engineer.v2025-10-27.q109 Dumps
