SIMULATION
Before Making any changes build the Dockerfile with tag base:v1
Now Analyze and edit the given Dockerfile(based on ubuntu 16:04)
Fixing two instructions present in the file, Check from Security Aspect and Reduce Size point of view.
Dockerfile:
FROM ubuntu:latest
RUN apt-get update -y
RUN apt install nginx -y
COPY entrypoint.sh /
RUN useradd ubuntu
ENTRYPOINT ["/entrypoint.sh"]
USER ubuntu
entrypoint.sh
#!/bin/bash
echo "Hello from CKS"
After fixing the Dockerfile, build the docker-image with the tag base:v2 To Verify: Check the size of the image before and after the build.
SIMULATION
Enable audit logs in the cluster, To Do so, enable the log backend, and ensure that
1. logs are stored at /var/log/kubernetes/kubernetes-logs.txt.
2. Log files are retained for 5 days.
3. at maximum, a number of 10 old audit logs files are retained.
Edit and extend the basic policy to log:
1. Cronjobs changes at RequestResponse
2. Log the request body of deployments changes in the namespace kube-system.
3. Log all other resources in core and extensions at the Request level.
4. Don't log watch requests by the "system:kube-proxy" on endpoints or
SIMULATION
Enable audit logs in the cluster, To Do so, enable the log backend, and ensure that
1. logs are stored at /var/log/kubernetes-logs.txt.
2. Log files are retained for 12 days.
3. at maximum, a number of 8 old audit logs files are retained.
4. set the maximum size before getting rotated to 200MB
Edit and extend the basic policy to log:
1. namespaces changes at RequestResponse
2. Log the request body of secrets changes in the namespace kube-system.
3. Log all other resources in core and extensions at the Request level.
4. Log "pods/portforward", "services/proxy" at Metadata level.
5. Omit the Stage RequestReceived
All other requests at the Metadata level
Using the runtime detection tool Falco, Analyse the container behavior for at least 30 seconds, using filters that detect newly spawning and executing processes
You must complete this task on the following cluster/nodes:
Cluster: trace
Master node: master
Worker node: worker1
You can switch the cluster/configuration context using the following command:
[desk@cli] $ kubectl config use-context trace
Given: You may use Sysdig or Falco documentation.
Task:
Use detection tools to detect anomalies like processes spawning and executing something weird frequently in the single container belonging to Pod tomcat.
Two tools are available to use:
1. falco
2. sysdig
Tools are pre-installed on the worker1 node only.
Analyse the container's behaviour for at least 40 seconds, using filters that detect newly spawning and executing processes.
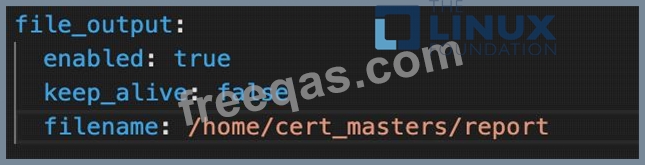
Store an incident file at /home/cert_masters/report, in the following format:
[timestamp],[uid],[processName]
Note: Make sure to store incident file on the cluster's worker node, don't move it to master node.
Enter your email address to download LinuxFoundation.CKS.v2022-03-11.q25 Dumps
