Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text and numerical values. 75% of the rows contain description data that has an average length of 1.1 MB.
You plan to copy the data from the storage account to an Azure SQL data warehouse.
You need to prepare the files to ensure that the data copies quickly.
Solution: You modify the files to ensure that each row is more than 1 MB.
Does this meet the goal?
You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1.
You need to determine the size of the transaction log file for each distribution of DW1.
What should you do?
A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet the following requirements:
Ingest:
Access multiple data sources.
Provide the ability to orchestrate workflow.
Provide the capability to run SQL Server Integration Services packages.
Store:
Optimize storage for big data workloads.
Provide encryption of data at rest.
Operate with no size limits.
Prepare and Train:
Provide a fully-managed and interactive workspace for exploration and visualization.
Provide the ability to program in R, SQL, Python, Scala, and Java.
Provide seamless user authentication with Azure Active Directory.
Model & Serve:
Implement native columnar storage.
Support for the SQL language
Provide support for structured streaming.
You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You need to design the partitions for the product sales transactions. The solution must meet the sales transaction dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You use PySpark in Azure Databricks to parse the following JSON input.
You need to output the data in the following tabular format.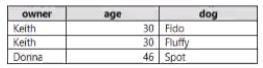
How should you complete the PySpark code? To answer, drag the appropriate values to he correct targets. Each value may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

