What should you recommend using to ingest the customer data into the data store in the AnatyticsPOC workspace?
You have a Fabric tenant that contains a lakehouse.
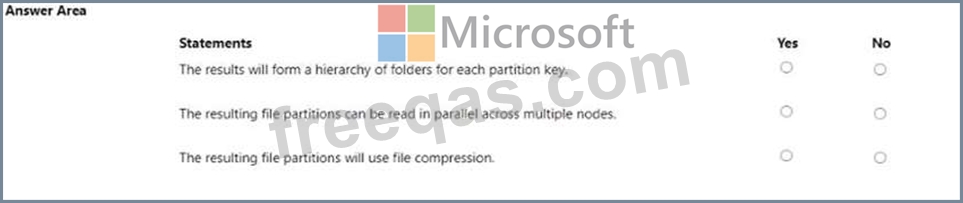
You are using a Fabric notebook to save a large DataFrame by using the following code.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.